




合作客戶/
拜耳公司 |
同濟大學 |
聯合大學 |
美國保潔 |
美國強生 |
瑞士羅氏 |






相關新聞Info
推薦新聞Info
-
> 微通道流動沸騰中表面張力的關鍵作用機制研究(三)
> 微通道流動沸騰中表面張力的關鍵作用機制研究(二)
> 微通道流動沸騰中表面張力的關鍵作用機制研究(一)
> 電場電壓對明膠液滴荷質比、表面張力的影響及預測模型構建(三)
> 電場電壓對明膠液滴荷質比、表面張力的影響及預測模型構建(二)
> 電場電壓對明膠液滴荷質比、表面張力的影響及預測模型構建(一)
> 破解固態電池界面之困:表面張力調控SiO?氣凝膠電解質原位構筑新策略
> 聯結基對磺酸鹽型雙子表面活性劑界面行為及泡沫穩定性的作用機制(三)
> 聯結基對磺酸鹽型雙子表面活性劑界面行為及泡沫穩定性的作用機制(二)
> 聯結基對磺酸鹽型雙子表面活性劑界面行為及泡沫穩定性的作用機制(一)
電場電壓對明膠液滴荷質比、表面張力的影響及預測模型構建(一)
來源:包裝工程(技術欄目) 瀏覽 58 次 發布時間:2026-01-23
摘要
目的探究不同荷質比明膠溶液的潤濕性能,并建立預測模型。方法以明膠可食涂膜為研究對象,利用感應荷電施加外源靜電場以改善膜液潤濕性能,探究電場電壓對明膠液滴荷質比與表面張力,以及液滴在疏水表面接觸角的影響,并通過機器學習建立荷質比與表面張力/接觸角之間預測模型。結果隨著電壓升高,明膠液滴荷質比不斷增大,且僅以司盤20為表面活性劑(tw0組)時液滴具有最高的荷質比(-50 nC/g)。在0~7kV內,明膠液滴的表面張力隨電壓升高從35.99~40.65 mN/m降至31.38~35.65 mN/m,其中tw0組表面張力下降最為明顯。明膠液滴在石蠟表面的接觸角也隨電壓升高而減小,在表面活性劑吐溫20與司盤20質量比為1:1時具有最小值,即電壓7kV時接觸角為64.99°。深度神經網絡預測模型決定系數接近于1,均方誤差小于0.08,平均絕對誤差小于0.15,具有最好的預測效果。結論靜電噴涂能夠有效改善膜液在食品表面的潤濕性能,利用深度神經網絡能夠建立膜液液滴荷質比與表面張力/接觸角的良好預測模型。
1 實驗
1.1 實驗材料與設備
主要材料:明膠(藥用級,CAS:9000-70-8),購買于上海阿拉丁生化科技股份有限公司;吐溫20、司盤20和甘油等均為國產分析純,購買于上海易恩化學技術有限公司;電極環為304不銹鋼(外徑為78mm,內徑為68mm)。
主要儀器:DW-P303高壓電源,天津東文高壓電源有限公司;LFY數字電荷儀,北京中慧天誠科技有限公司;DAS100接觸角測量儀,德國克呂士公司。
1.2 明膠可食性成膜溶液的制備
稱取7.5g明膠顆粒加入250mL去離子水中,加入質量分數為30%(基于明膠質量)的甘油,70℃下混合攪拌30min,加入質量分數為0.05%(基于溶劑質量)的表面活性劑(具體分組和配比見表1)并攪拌30min,混合溶液超聲1h(超聲功率為900W),備用。
表1 各組明膠成膜溶液所添加表面活性劑比例| 組名 | 吐溫20質量分數/% | 司盤20質量分數/% |
|---|---|---|
| tw0 | 0 | 100 |
| tw20 | 20 | 80 |
| tw35 | 35 | 65 |
| tw50 | 50 | 50 |
| tw65 | 65 | 35 |
| tw80 | 80 | 20 |
| tw100 | 100 | 0 |
1.3 實驗系統及測試方法
明膠成膜溶液液滴感應荷電的原理圖與實際搭建平臺如圖1所示。該平臺由微量進樣針、高壓電源、數字電荷儀、法拉第筒、接觸角測量儀等組成,微量進樣針針尖穿過電極環下平面4mm。利用高壓電源給電極環通上高壓正電,在靜電感應的作用下給微量進樣針針頭處膜液荷上負電。
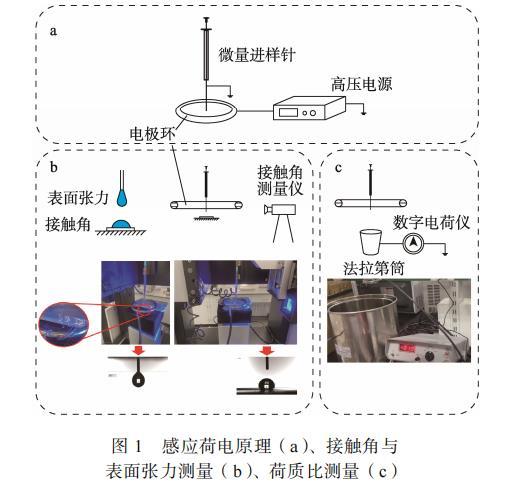
圖1 感應荷電原理(a)、接觸角與表面張力測量(b)、荷質比測量(c)
1.4 荷質比的測量
荷質比的測量原理如圖 1所示,調節電極環不同電壓,向法拉第筒中滴人明膠溶液,記錄數字電荷儀示數并稱重。為確保充分荷電,每次滴液間隔 1min,實驗重復8次。
1.5 表面張力的測量
基于懸滴法原理,采用接觸角測量儀測定表面張力,相同條件下重復 8次實驗。
1.6 接觸角的測量
使用石蠟模擬疏水性食品表面,明膠溶液滴的接觸角通過接觸角測量儀測量。調節不同電壓,將 5μL 的液滴緩慢滴到石蠟表面,并在 30s后記錄接觸角,使用橢圓擬合的方法來測定接觸角,相同條件下進行8次重復實驗。
1.7 數據預處理
在進行神經網絡學習之前,需要對實驗數據進行有效預處理以確保模型的訓練效果。首先,對表面張力、接觸角和荷質比的測量數據進行整理,處理潛在異常值。這包括檢測并刪除可能由于實驗誤差引起的異常數據點,以確保輸入模型的數據質量。然后,將整理過的數據集劃分為訓練集(80%)和測試集(20%),這有助于提高模型的泛化能力。
1.8 機器學習
使用PyTorch框架進行機器學習神經網絡的搭建和訓練。首先,設計包括多個層次的全連接層和激活函數,以捕捉潛在的數量關系。在選擇損失函數時,選擇均方誤差(Mean Squared Error, MSE)這一適合回歸問題的損失函數。優化器選擇 Adam優化器。經多輪訓練,監控模型性能以及損失函數的收斂情況,通過調節神經網絡的超參數,如學習率、隱藏層節點數等,優化模型性能。
采用多種機器學習算法,包括 DNN(深度神經網絡)、 LR(線性回歸)、基于 2種核函數的 SVM(支持向量機)、DTR(決策樹回歸)、GBR(梯度增強回歸)、 KNN(K近鄰),評估荷質比與表面張力、接觸角的關系,確定最優預測模型。
按照 8: 2的比例將實驗數據劃分為訓練集和測試集,對每個模型進行訓練,并在測試集上進行驗證。這里選用 3種常用于回歸任務的評價指標:均方誤差(MSE)、平均絕對誤差(MAE)和決定系數 R2。 MSE和 MAE可以衡量預測值與真實值之間的誤差,數值越小表示模型預測的越準確; R2 度量模型擬合數據的程度,取值范圍在 0到 1之間,越接近 1表示模型對數據的擬合程度越好。這 3個評價指標的計算公式如下所示:
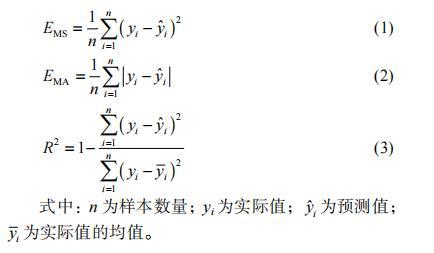
式中: n為樣本數量; y_i 為實際值; ?_i 為預測值; ?_i 為實際值的均值。
1.9 數據處理與統計分析
數據結果表示為平均值±標準偏差的形式,采用SPSS Statistics(24, IBM公司,美國)進行方差分析, P≤0.05 則認為數據有顯著性差異。